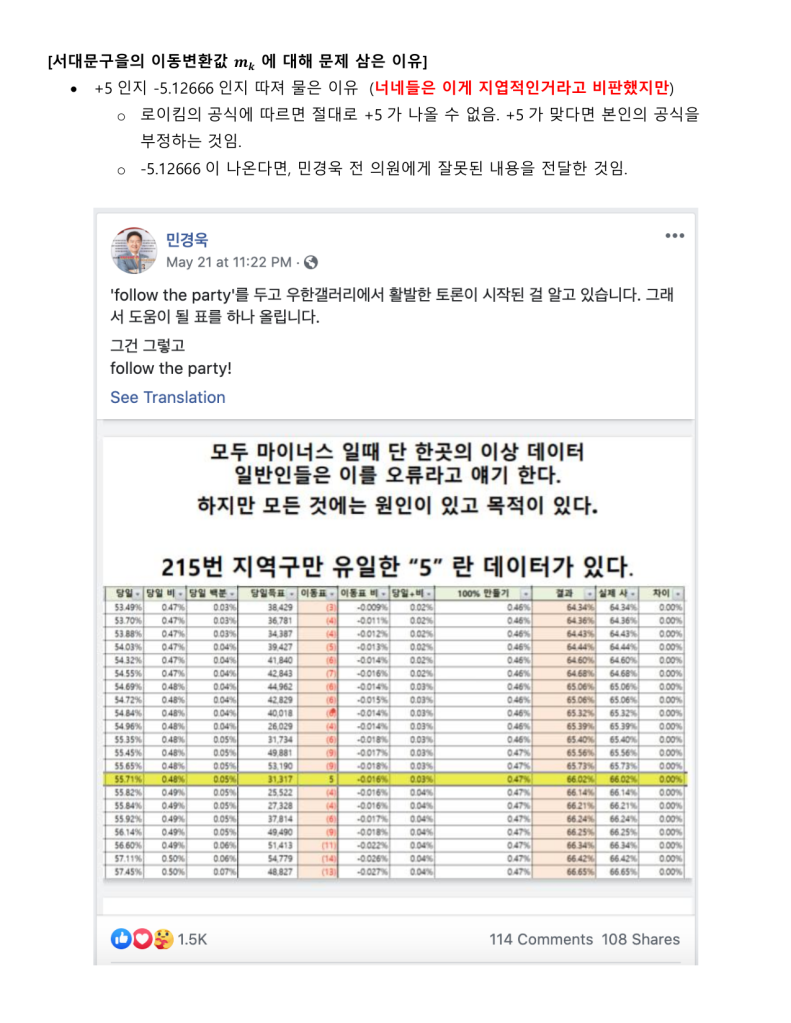
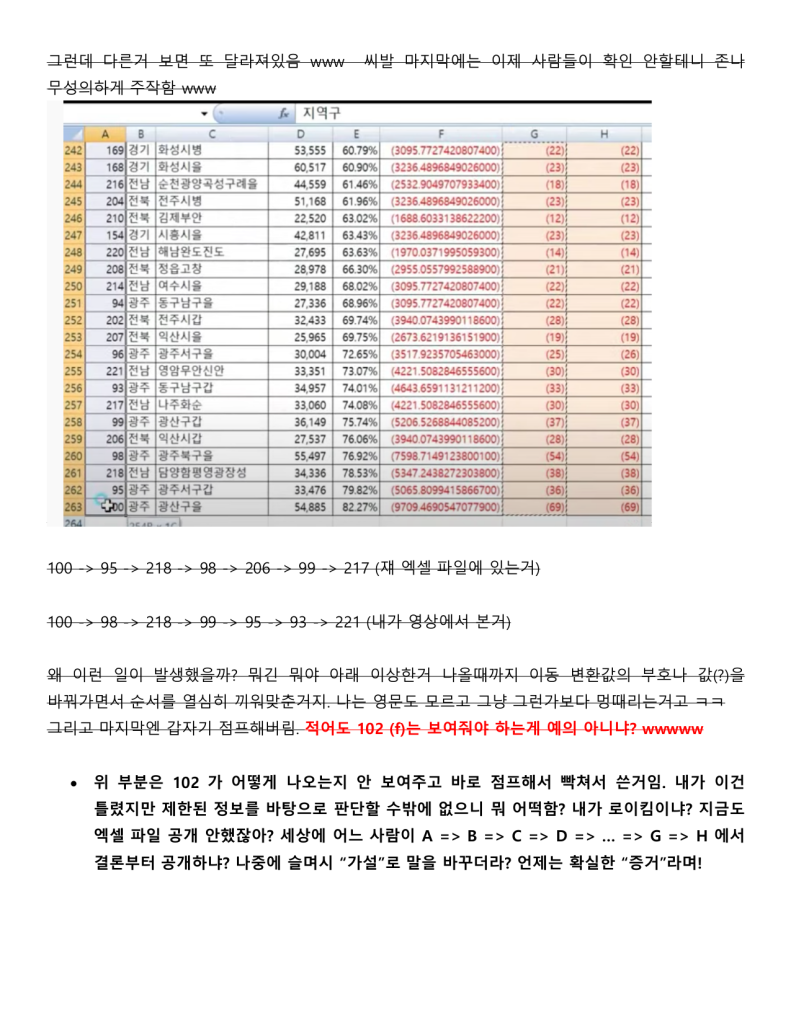
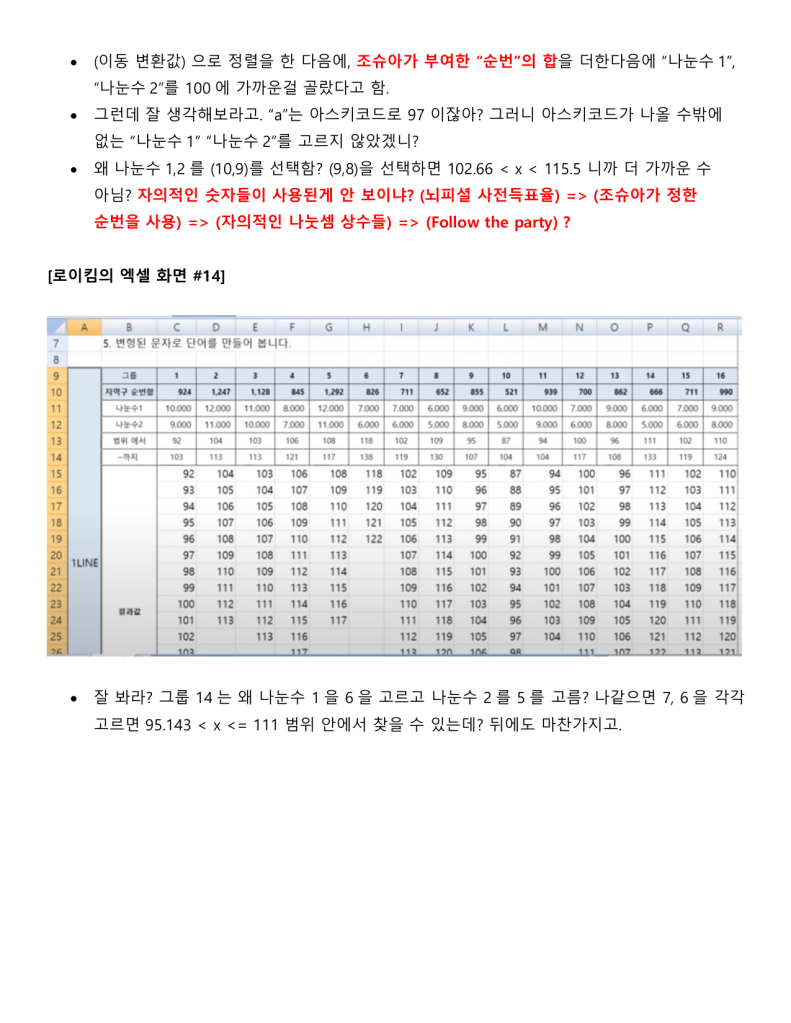
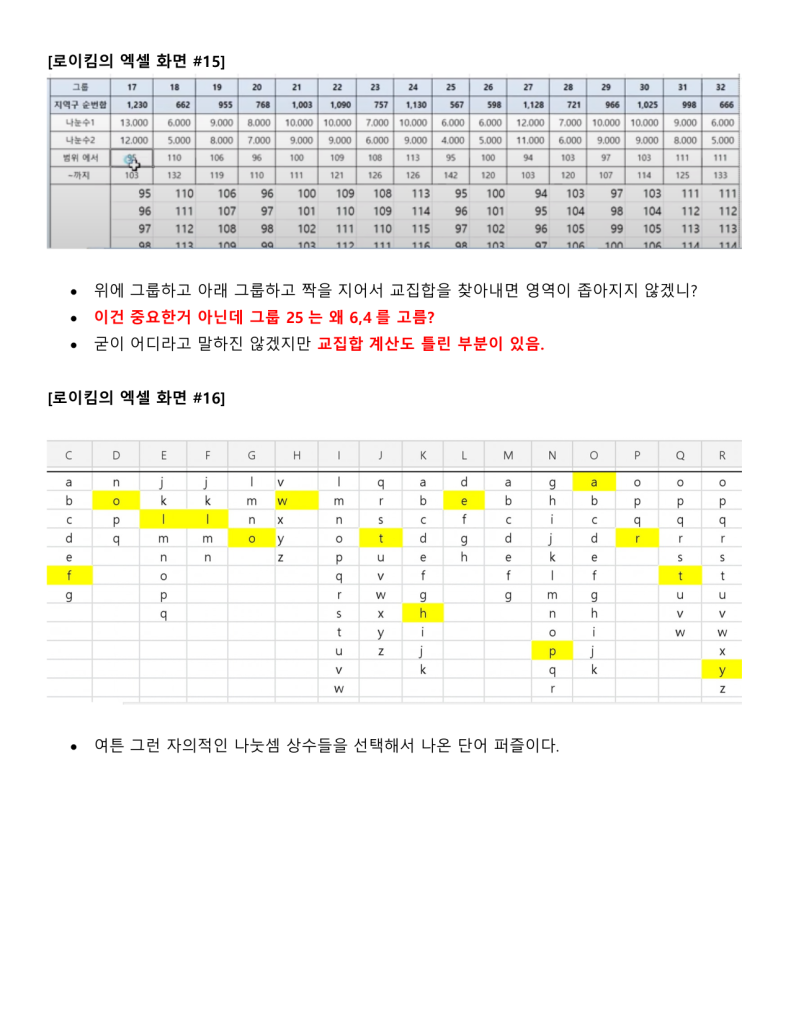
정보시스템 설계와 개발에 30여년을 종사한 사람으로써 지난 한달여간 로이킴 방정식을 분석하고 해석하고 시스템화를 하고자 했을 때 문제점을 파악하여 나름 지금 현재는 코딩을 시작 할 수 있는 정도의 상세설계 즉 Logic이 다 파악되었다고 생각 하고 있습니다.
이 답변을 읽기 위해서는 다음과 같은 전제에 동의를 해야 합니다.
1. 로이킴은 Reverse Engineering(역공학)을 통하여 즉 역으로 모든 것을 분석하고 체계화 하였는데 실제 시스템 설계 및 개발에 대한 경험이 없는 관계로 기초설계, 기본설계, 상세설계, 프로그래밍이라는 정상적인 설계문서가 나오는 체계를 따라가지 못하였고 당연히 문서들 간 또는 정리하는 과정에서 불일치 하는 부분들이 있었으나 의도된 것이 아니며 본인은 그것들을 하나하나 확인 및 해결해 가면서 로이킴 방정식 및 ftp가 맞다고 동의하게 되었습니다.
2. 로이킴 방정식을 역방향으로 이해하려고 하면 어렵습니다. 그래서 정방향 즉 원래 시스템 설계/개발 방식인 기초, 기본, 상세, 프로그래밍 순으로 먼저 설명을 하면서 역방향으로 파악된 로이킴 가설과 일치시키는 단계를 밟도록 하겠습니다.
3. 이 문서를 읽는 분들은 고등학교 이상의 수학교육을 받았다는 전제하에 기술하겠습니다.
전제 :
1. 당일투표에 대한 투개표가 모두 이루어져 각 선거구별 투표수와 후보자별 지지율이 모두 확정된 상태임. 즉 각 선거구별 확정된 당일 투표 결과를 기준으로 당선시키고자 하는 정당후보자의 사전투표 결과를 원하는 대로 컨트롤 할 수 있다면 해당 선거구의 당락을 좌지우지 할 수 있음.
2. 목표로 하는 범위로 컨트롤 하기 위해서는 쓸 수 있는 여유 표가 있어야 하는데 그것이 디지털 게리멘더링 용어로 정의되었으며 당선이 확실한 선거구로부터 표를 가져와 경합지역 또는 열세지역 선거구에 배분한다는 것이 시스템을 개발한다고 하면 기초설계에서 검토/확정된 로직임
단계 1. 사전득표율 방정식의 유도
고려사항 : 각 선거구에서 획득하고자 하는 사전득표 계산 로직을 개발 시 해당 선거구의 정당지지율과 투표수 규모를 고려해서 하여야 한다. 그렇지 않으면 투표수 규모나 지지율에 따른 왜곡된 분배 값이 계산 될 수 있다.
각 선거구 사전득표 = 지지율(A) * 지지율 보정값(x) + 투표수규모(B) * 투표수 보정값(z)
사전투표 산정을 식으로 표현하면 다음과 같다
y = A*x + B*z, 단 x는 정당지지율 비중에 대한 보정값, z는 투표수규모비중에 대한 보정값
각 산거구에 대해서 식으로 표현하면 다음과 같다.
선거구 1 : y1 = A1*x1 + B1*z1
선거구 2 : y2 = A2*x2 + B2*z2
…… 중략 …..
선거구 253 : y253 = A253*x253 + B253*z253
253개 선거구 전체에 대해서 각 목표로 하는 당선자 수를 달성하기 위한 각 선거구별 보정비율(x,z)을 도출 해 내야 하는데 253개 식에 506개의 변수값을 조절하여 해를 구하고자 할 때 컴퓨터 시뮬레이션 소요시간을 줄이기 위해서는 변수의 숫자를 줄이는 것이 필요하다.
그래서 다음과 같이 식을 유도 한다.
변수 수를 줄이기 위하여 한번 더 식을 유도 한다. (이하 언급 시 식 이름: 사전득표계산식)
선거구 1 : y1 = (A1 + B1 * f1) * k
선거구 2 : y2 = (A2 + B2 * f2) * k
…… 중략 …..
선거구 253 : y253 = (A253 + B253 * f253) * k
이와 같이 식을 간략화 하여 전체 적인 게리멘더링에 따른 분배를 하면서 각 선거구 사전득표를 계산 해 낼 수 있다면 변수의 수는 506개에서 254개로 줄어 들어 실제 운영 시 내가 사용 할 수 있는 시간이 한정된 상황에서 최소의 시간으로 해를 구 할 수 있는 최적의 방법이 되는 것이다.
253개 식, 254개 변수가 존재하는 상황에서 식 전체를 만족시키는 변수 값 즉 해를 사람에 의해서 수계산으로 값을 찾는 것은 무모한 일이며, 산업계에서는 이보다도 훨씬 많은 식과 변수 개수가 존재하는 상황의 해를 구하는 시스템들이 부지기수로 있다.
즉 해를 구하는 것은 사람이 아니라 기계, 즉 프로그램이 훨씬 더 반복적 iteration을 잘하고 또한 해를 구할 때 무식하게 253의 253승으로 해를 구하는 방식으로 접근하는 프로그램은 발도 붙이지 못하며 접근방법에 대한 알고리즘을 어떻게 개발하느냐에 따라 성능이 기하급수적으로 차이나며 수많은 변수와 제약을 만족시키는 해를 빠른 시간에 구해주는 알고리즘프로그램이 비싼 이유가 그 만큼 값어치를 하기 때문이다. 즉 빨리 해를 구해주면 더많은 Case Study를 통해서 이익을 더 많이 내 줄 수 있는 조건과 제약을 찾아낼 수 있기 때문에 비싼 프로그램 가격을 지불 하더라도 기꺼이 그런 프로그램을 사는 것입니다.
단계 2. 사전득표계산식과 로이킴 방정식의 동기화
이해 동기화 : 현실세계에서 사전득표계산식의 변수값들은 컴퓨터가 값을 찾아주지 사람이 수계산을 하지 않습니다.
시전득표계산식 : y = ( A + B*f ) * k
로이킴 식 :
민주당 사전투표율
= {(당일지역득표율/총당일득표율+이동값/당일득표수)+0.00072228%} x 이동값/이동변환값
식을 방정식 체계로 정리하면
민주당 사전투표율
= {(당일지역득표율/총당일득표율+이동값/당일득표수)} x 이동값/이동변환값
단, 전체선거구의 {(당일지역득표율/총당일득표율+이동값/당일득표수)}의 합 = 1
사전득표 계산식과 비교하여 로이킴이 찾아낸 A,B,f,k 값은 다음과 같습니다.
A : 당일지역득표율/총당일득표율
B : 1/당일 득표수
f : 이동값
k : 이동값/이동변환값 (= 최적화 상수)
이후 설명을 위하여 k에 대한 정의는 최적화 상수로 하겠습니다.
(실제로 목표값 상수로도 불리며, 로이킴이 붙이지 않았지만 다른 분들이 마법의 상수라고 붙인 이 이름은 맞지 않습니다. 마법 하면 속임으로 잘못된 뉘앙스를 줄 수 있기 때문에 사용하지 마시기 바랍니다.)
상기 설명을 통해서 로이킴이 찾아낸 식이 실제 기초/기본설계를 했을 때 어떻게 설계와 연결 될 수 있는 지 말씀 드렸습니다.
이 단계를 마무리 하기전에 로이킴은 253개 식의 254개 변수 값을 컴퓨터 시뮬레이션이 아닌 자신의 숫자 감감 능력과 시행 착오를 통해 찾아 내었으며 실제 컴퓨터 시뮬레이션을 통해 구해낸 답과 일부 차이가 있을 수 있습니다. 제 생각으로는 컴퓨터는 시간적 제약 만 없다면 253의 253승번 계산을 통해 가장 최적의 답을 찾겠지만 사람은 그렇게 할 수가 없기 때문에 로이킴은 최선을 다해 찾아낸 값이 여러분들이 알고 있는 이동값이며 최적화 상수입니다.
이런 계산을 할 수 없는 범인들이 이 값을 어떻게 찾아 냈는지 논리적으로 이해하려면 로이킴이 작성 공개한 논문의 이해부터 시도해야 할 것입니다.
상기 내용에 대한 이해와 합의가 되어야 다음단계에 대한 동기화된 진행이 될 수 있는 관계로
상기 기술된 내용에 대한 의견을 주시면 반영한 후 나머지 제기된 내용들에 대해 정방향 즉 설계를 해가는 단계를 기준으로 계속 설명을 드리겠습니다.

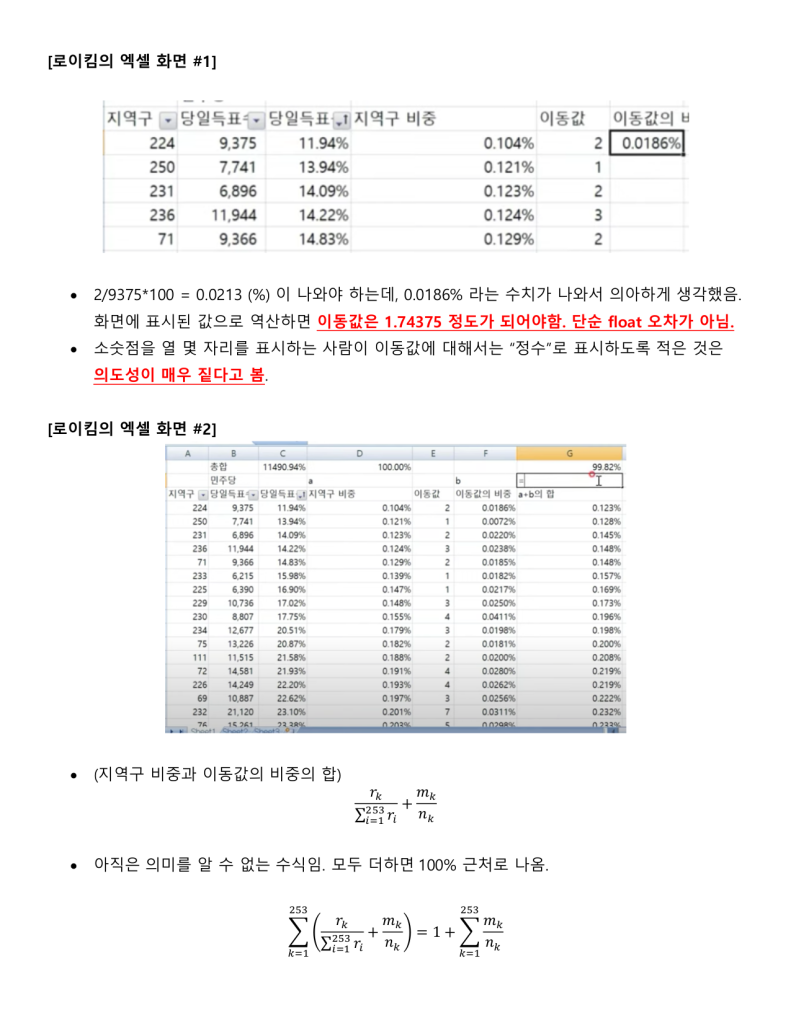
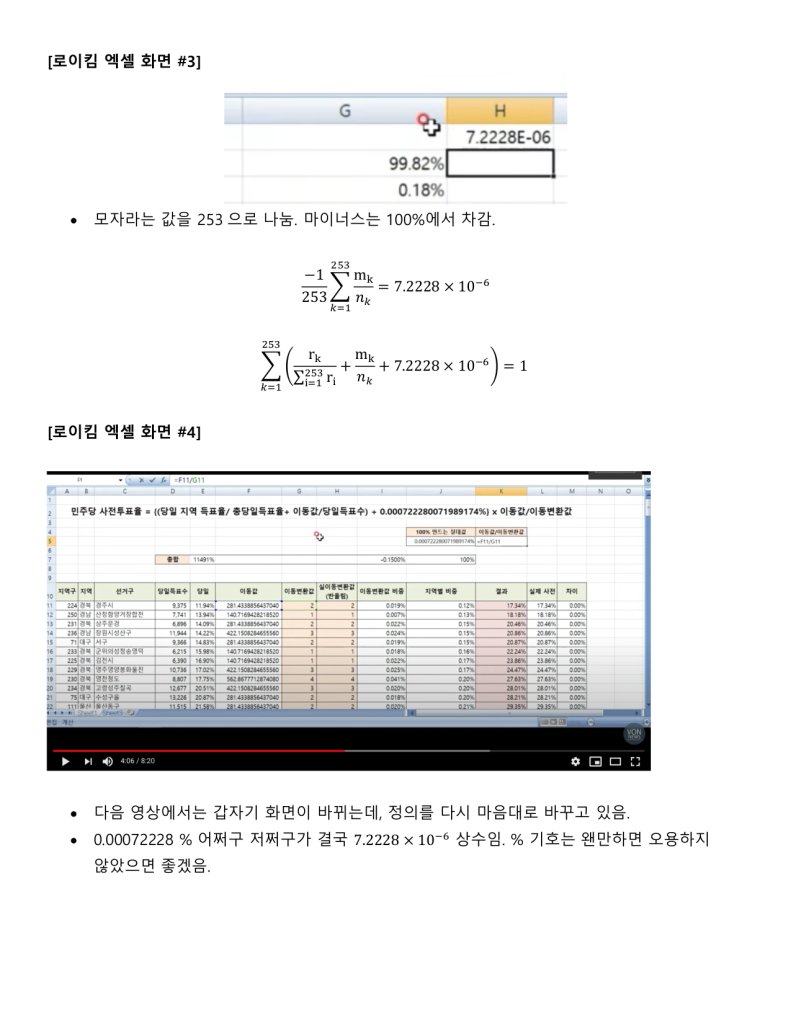



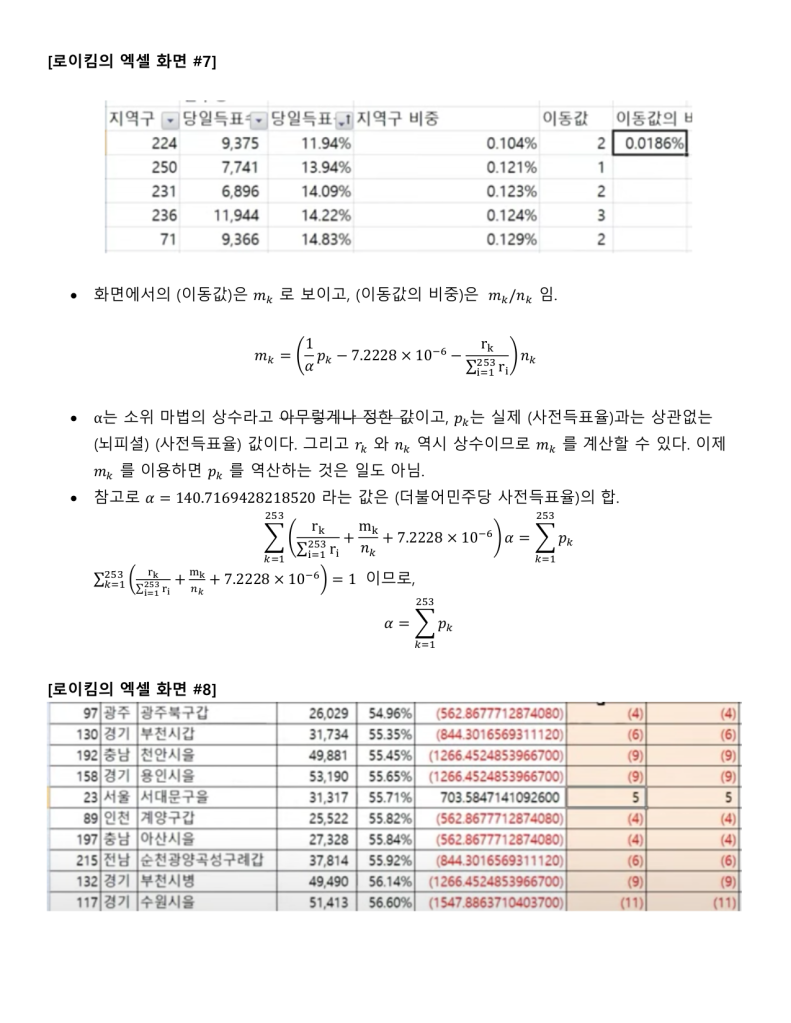
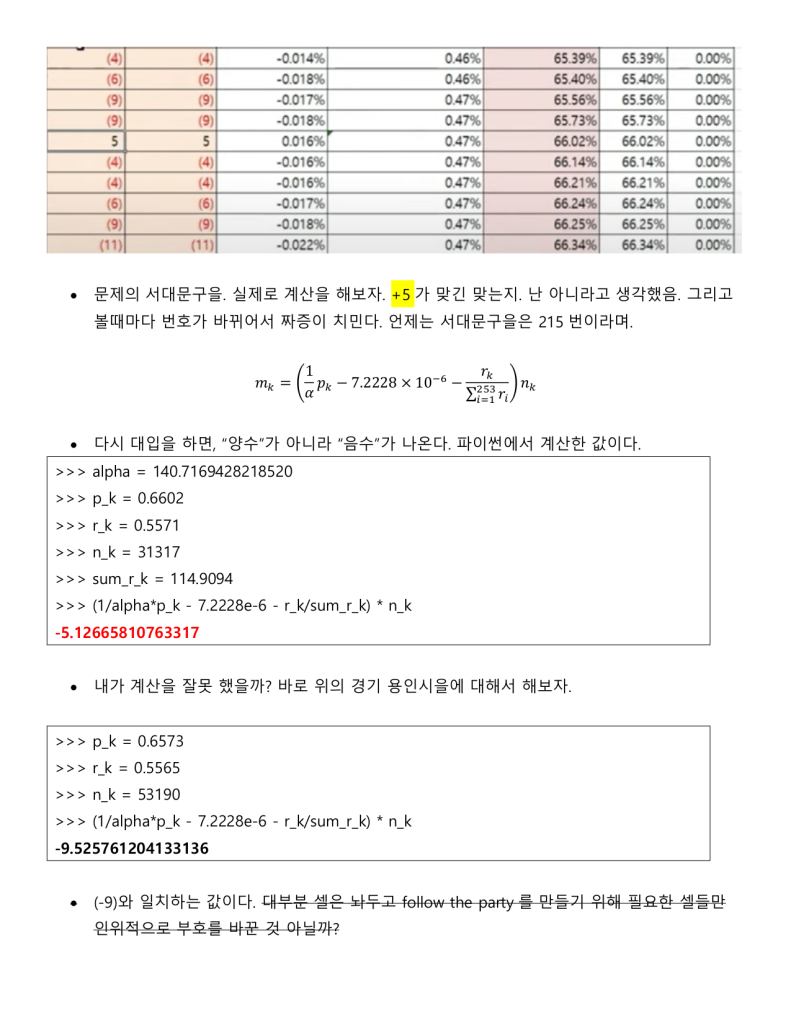









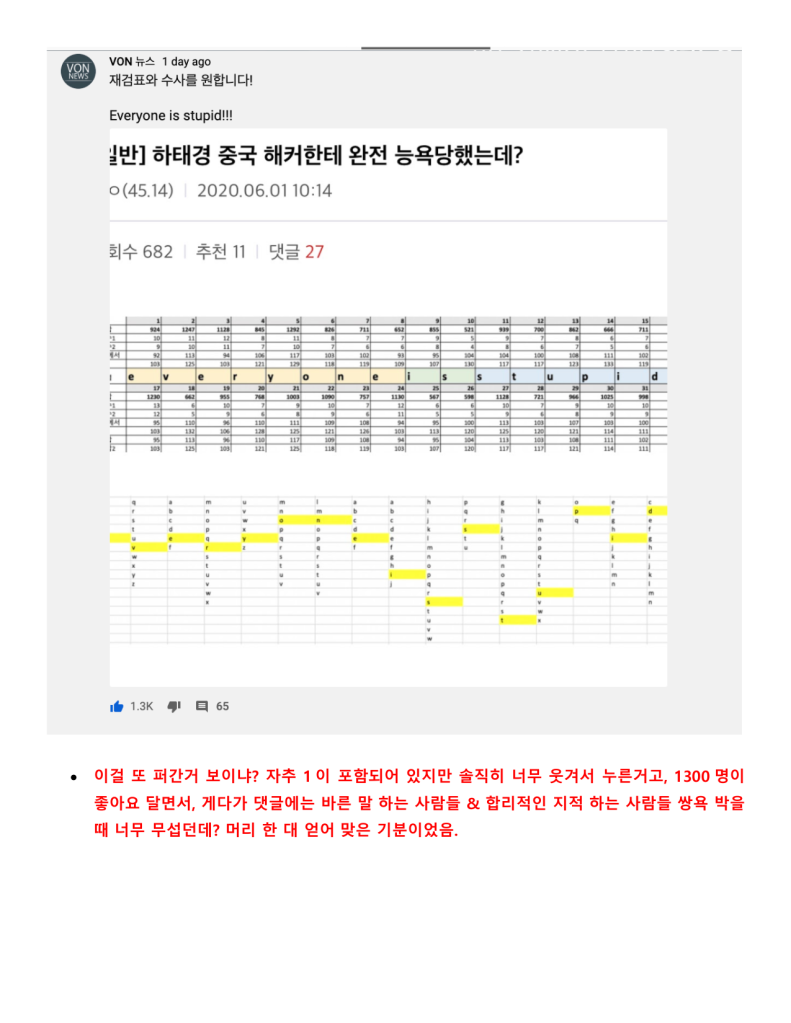


정보시스템 설계와 개발에 30여년을 종사한 사람으로써 지난 한달여간 로이킴 방정식을 분석하고 해석하고 시스템화를 하고자 했을 때 문제점을 파악하여 나름 지금 현재는 코딩을 시작 할 수 있는 정도의 상세설계 즉 Logic이 다 파악되었다고 생각 하고 있습니다.
이 답변을 읽기 위해서는 다음과 같은 전제에 동의를 해야 합니다.
1. 로이킴은 Reverse Engineering(역공학)을 통하여 즉 역으로 모든 것을 분석하고 체계화 하였는데 실제 시스템 설계 및 개발에 대한 경험이 없는 관계로 기초설계, 기본설계, 상세설계, 프로그래밍이라는 정상적인 설계문서가 나오는 체계를 따라가지 못하였고 당연히 문서들 간 또는 정리하는 과정에서 불일치 하는 부분들이 있었으나 의도된 것이 아니며 본인은 그것들을 하나하나 확인 및 해결해 가면서 로이킴 방정식 및 ftp가 맞다고 동의하게 되었습니다.
2. 로이킴 방정식을 역방향으로 이해하려고 하면 어렵습니다. 그래서 정방향 즉 원래 시스템 설계/개발 방식인 기초, 기본, 상세, 프로그래밍 순으로 먼저 설명을 하면서 역방향으로 파악된 로이킴 가설과 일치시키는 단계를 밟도록 하겠습니다.
3. 이 문서를 읽는 분들은 고등학교 이상의 수학교육을 받았다는 전제하에 기술하겠습니다.
전제 :
1. 당일투표에 대한 투개표가 모두 이루어져 각 선거구별 투표수와 후보자별 지지율이 모두 확정된 상태임. 즉 각 선거구별 확정된 당일 투표 결과를 기준으로 당선시키고자 하는 정당후보자의 사전투표 결과를 원하는 대로 컨트롤 할 수 있다면 해당 선거구의 당락을 좌지우지 할 수 있음.
2. 목표로 하는 범위로 컨트롤 하기 위해서는 쓸 수 있는 여유 표가 있어야 하는데 그것이 디지털 게리멘더링 용어로 정의되었으며 당선이 확실한 선거구로부터 표를 가져와 경합지역 또는 열세지역 선거구에 배분한다는 것이 시스템을 개발한다고 하면 기초설계에서 검토/확정된 로직임
단계 1. 사전득표율 방정식의 유도
고려사항 : 각 선거구에서 획득하고자 하는 사전득표 계산 로직을 개발 시 해당 선거구의 정당지지율과 투표수 규모를 고려해서 하여야 한다. 그렇지 않으면 투표수 규모나 지지율에 따른 왜곡된 분배 값이 계산 될 수 있다.
각 선거구 사전득표 = 지지율(A) * 지지율 보정값(x) + 투표수규모(B) * 투표수 보정값(z)
사전투표 산정을 식으로 표현하면 다음과 같다
y = A*x + B*z, 단 x는 정당지지율 비중에 대한 보정값, z는 투표수규모비중에 대한 보정값
각 산거구에 대해서 식으로 표현하면 다음과 같다.
선거구 1 : y1 = A1*x1 + B1*z1
선거구 2 : y2 = A2*x2 + B2*z2
…… 중략 …..
선거구 253 : y253 = A253*x253 + B253*z253
253개 선거구 전체에 대해서 각 목표로 하는 당선자 수를 달성하기 위한 각 선거구별 보정비율(x,z)을 도출 해 내야 하는데 253개 식에 506개의 변수값을 조절하여 해를 구하고자 할 때 컴퓨터 시뮬레이션 소요시간을 줄이기 위해서는 변수의 숫자를 줄이는 것이 필요하다.
그래서 다음과 같이 식을 유도 한다.
선거구 1 : y1 = (A1 + B1*z1/x1) * x1
선거구 2 : y2 = (A2 + B2*z2/x2) * x2
…… 중략 …..
선거구 253 : y253 = (A253 + B253*z253/x253) * x253
변수 수를 줄이기 위하여 한번 더 식을 유도 한다. (이하 언급 시 식 이름: 사전득표계산식)
선거구 1 : y1 = (A1 + B1 * f1) * k
선거구 2 : y2 = (A2 + B2 * f2) * k
…… 중략 …..
선거구 253 : y253 = (A253 + B253 * f253) * k
이와 같이 식을 간략화 하여 전체 적인 게리멘더링에 따른 분배를 하면서 각 선거구 사전득표를 계산 해 낼 수 있다면 변수의 수는 506개에서 254개로 줄어 들어 실제 운영 시 내가 사용 할 수 있는 시간이 한정된 상황에서 최소의 시간으로 해를 구 할 수 있는 최적의 방법이 되는 것이다.
253개 식, 254개 변수가 존재하는 상황에서 식 전체를 만족시키는 변수 값 즉 해를 사람에 의해서 수계산으로 값을 찾는 것은 무모한 일이며, 산업계에서는 이보다도 훨씬 많은 식과 변수 개수가 존재하는 상황의 해를 구하는 시스템들이 부지기수로 있다.
즉 해를 구하는 것은 사람이 아니라 기계, 즉 프로그램이 훨씬 더 반복적 iteration을 잘하고 또한 해를 구할 때 무식하게 253의 253승으로 해를 구하는 방식으로 접근하는 프로그램은 발도 붙이지 못하며 접근방법에 대한 알고리즘을 어떻게 개발하느냐에 따라 성능이 기하급수적으로 차이나며 수많은 변수와 제약을 만족시키는 해를 빠른 시간에 구해주는 알고리즘프로그램이 비싼 이유가 그 만큼 값어치를 하기 때문이다. 즉 빨리 해를 구해주면 더많은 Case Study를 통해서 이익을 더 많이 내 줄 수 있는 조건과 제약을 찾아낼 수 있기 때문에 비싼 프로그램 가격을 지불 하더라도 기꺼이 그런 프로그램을 사는 것입니다.
단계 2. 사전득표계산식과 로이킴 방정식의 동기화
이해 동기화 : 현실세계에서 사전득표계산식의 변수값들은 컴퓨터가 값을 찾아주지 사람이 수계산을 하지 않습니다.
시전득표계산식 : y = ( A + B*f ) * k
로이킴 식 :
민주당 사전투표율
= {(당일지역득표율/총당일득표율+이동값/당일득표수)+0.00072228%} x 이동값/이동변환값
식을 방정식 체계로 정리하면
민주당 사전투표율
= {(당일지역득표율/총당일득표율+이동값/당일득표수)} x 이동값/이동변환값
단, 전체선거구의 {(당일지역득표율/총당일득표율+이동값/당일득표수)}의 합 = 1
사전득표 계산식과 비교하여 로이킴이 찾아낸 A,B,f,k 값은 다음과 같습니다.
A : 당일지역득표율/총당일득표율
B : 1/당일 득표수
f : 이동값
k : 이동값/이동변환값 (= 최적화 상수)
이후 설명을 위하여 k에 대한 정의는 최적화 상수로 하겠습니다.
(실제로 목표값 상수로도 불리며, 로이킴이 붙이지 않았지만 다른 분들이 마법의 상수라고 붙인 이 이름은 맞지 않습니다. 마법 하면 속임으로 잘못된 뉘앙스를 줄 수 있기 때문에 사용하지 마시기 바랍니다.)
상기 설명을 통해서 로이킴이 찾아낸 식이 실제 기초/기본설계를 했을 때 어떻게 설계와 연결 될 수 있는 지 말씀 드렸습니다.
이 단계를 마무리 하기전에 로이킴은 253개 식의 254개 변수 값을 컴퓨터 시뮬레이션이 아닌 자신의 숫자 감감 능력과 시행 착오를 통해 찾아 내었으며 실제 컴퓨터 시뮬레이션을 통해 구해낸 답과 일부 차이가 있을 수 있습니다. 제 생각으로는 컴퓨터는 시간적 제약 만 없다면 253의 253승번 계산을 통해 가장 최적의 답을 찾겠지만 사람은 그렇게 할 수가 없기 때문에 로이킴은 최선을 다해 찾아낸 값이 여러분들이 알고 있는 이동값이며 최적화 상수입니다.
이런 계산을 할 수 없는 범인들이 이 값을 어떻게 찾아 냈는지 논리적으로 이해하려면 로이킴이 작성 공개한 논문의 이해부터 시도해야 할 것입니다.
상기 내용에 대한 이해와 합의가 되어야 다음단계에 대한 동기화된 진행이 될 수 있는 관계로
상기 기술된 내용에 대한 의견을 주시면 반영한 후 나머지 제기된 내용들에 대해 정방향 즉 설계를 해가는 단계를 기준으로 계속 설명을 드리겠습니다.
이후는 상세설계가 되겠지요..
그럼 1차 답변은 여기서 정리하겠습니다.
좋아요좋아요